Quantization
by MalrangCow
LM Studio에서 모델을 둘러보면 Q4_K_M, Q5_K_M 등으로 표시된 사양에 대해서 볼 수 있다.
이를 이해하려면 우선 양자화에 대해서 알아야 한다.
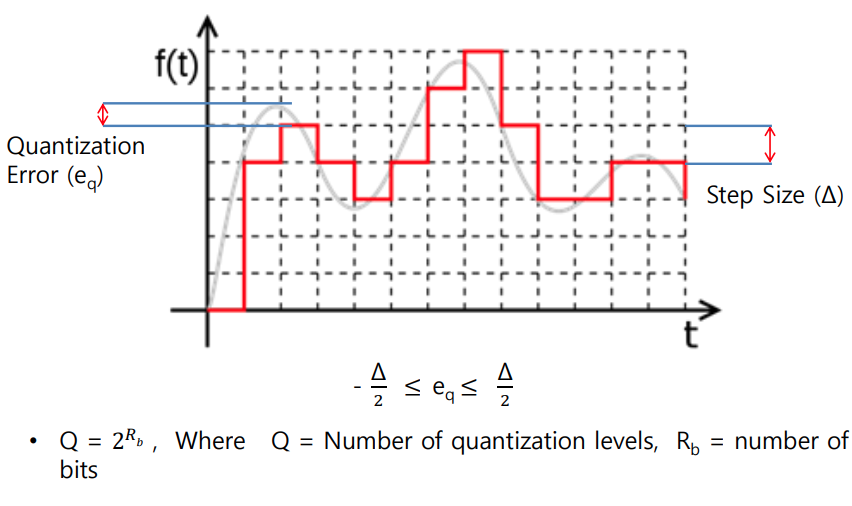
넓은 의미의 양자화는 연속적인 값을 특정한 값의 범위로 근사화하는 과정을 의미한다.
그렇다면 딥러닝에서 양자화란 무엇일까 ?
딥러닝에서의 양자화란, 모델의 파라미터를 lower bit로 표현함으로서 계산과 메모리 접근 속도를 높이는 경량화 기법이다. 정확히는 신경망의 가중치(weight)와 활성화 함수(activation function) 출력을 더 작은 비트의 수로 변환하는 방식으로 주로 32비트 부동소수점 연산을 8비트의 정수로 많이 변환한다. (일반적으로 pytorch나 tensorflow의 파라미터가 32비트 부동 소숫점 연산으로 fp32(float32)의 형태로 저장되기 때문)
양자화는 모델의 크기를 줄이고, 메모리 사용량을 줄이며, 연산 속도를 높이는 효과를 볼 수 있다. 하지만 그만큼 정밀도를 감소시키기 때문에 모델의 정확도를 떨어뜨릴 수 있다.
모델의 정확도를 떨어뜨리면서 양자화를 적용시키는 예시
- 모바일 기기나 에지 디바이스와 같이 계산 자원이 제한적인 환경에서 사용
- 실시간 추론이 필요한 시스템에서 빠른 모델 실행 속도를 요구하는 경우
- 대규모 모델을 배포하거나 저장할 때 메모리 사용량을 줄여야하는 경우
Subscribe via RSS
{kind=link}